Reinforcement Learning: Q-Learning
Q-Learning is a Reinforcement Learning algorithm. It enables an agent to decide what action to take under what circustances. It learns through accepting rewards.
Project Description
This project programs an agent to run on a grid-world using Q-Learning. The world is a 150 states world of 10x15 cells (rooms). The agent can go in any of four directions: up, down, left, right. At the limit of the room, the action leanding outside the room has no consequences, i.e. the agent position remains the same. Elsewhere, the agent moves by one cell in the chosen direction. There is a reward of 1 at location (4, 4). The episode terminates with the reception of a reward. After that, a new episode may begin. Discounting factor γ = 0.97. It uses a ε-Greedy policy where ε = 5%. The agent uses Q-Learning: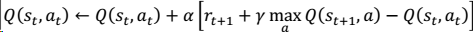 .
.
Pseudocode from Sutton & Barto, Reinforcement Learning: An introduction, 1998, Figure 6.12:

Techonology Used:
- Python
- Numpy
- Matplotlib
- Pandas
- Prettytable