Sentiment analysis, an area of Natural Language Processing (NLP), is the computational study that seeks people’s attitude, positive or negative, about a particular topic by analyzing their written sentences or documents. It is also known as opinion mining and concerned with people’s sentiments, opinions, attitude, evaluations, appraisals and emotions towards various entities such as products, organizations, services etc.
The application area of sentiment analysis is wide and very influential. Availability of big data from various sources has created opportunities to understand people’s opinion for various purposes. Sources include websites, company databases, government databases etc. Marketing, finance, political and social issues are some of the major application areas of it. However, performing sentiment analysis is not a trivial task. Usually, analysis is performed on big size data to get an accurate estimate of people’s sentiment. Automatic processing is thus needed to handle voluminous data. We need both good algorithms and fast processing systems in order to analyze and summarize people’s opinion. The process must be convenient and able to perform analysis within a reasonable amount of time. As an example, decision makers of an online business might need to check people’s opinion about their thousands of products on daily basis. For such a system sentiment analysis is needed to perform within the possible shortest time.
Distributed processing techniques such as MapReduce and platforms like Hadoop have created opportunities for doing such tasks very conveniently and quickly.
This project presents a sentiment analysis task performed in Hadoop environment using the MapReduce technique. Hadoop was accessed through the BigInsights service offered by the IBM cloud Bluemix. The sentiment analysis program was tested on a text file of 1.9 GB size. The obtained results were correct and the performance was satisfactory.
Techonology Used:
- Natural Language Processing
- Java
- MapReduce
- Apache Hadoop
- IBM BLuemix
Distributed Processing Technique and Platform
MapReduce
MapReduce is a software framework for writing applications that process large scale data in a distributed fashion. A MapReduce task can be divided into two phases, the map phase and the reduce phase. The map phase performs filtering and sorting, and the reduce phase performs a summary operation. Servers in MapReduce platform are organized in master-workers architecture. The master is responsible for interacting with the users. After receiving programs from users the master splits them into map and reduce works and assigns the works to the distributed servers over several nodes. Each mapper works independently and after processing produces <key, value> pairs which are fed to the reducer after sorting. The reducer reduces the input key-value pairs and generates output. User needs to write his own program for the map phase and the reduce phase. Below is a sample of input and output types of a MapReduce job.
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
Apache Hadoop
Hadoop is Apache’s free and open source implementation of the MapReduce framework. It is a project to develop open source software for flexible, scalable and distributed computing. Hadoop framework consists of the following four modules:
- Hadoop Distributed File System (HDFS): Commodity machines are used for storing data by HDFS. It has the capability to provide high aggregate bandwidth across the clusters.
- MapReduce: It is a programming model for large scale data processing.
- YARN: Yet Another Resource Negotiator (YARN) is a platform responsible for managing resources in clusters.
- Hadoop Common: It provides necessary libraries and utilities needed by other Hadoop programs.
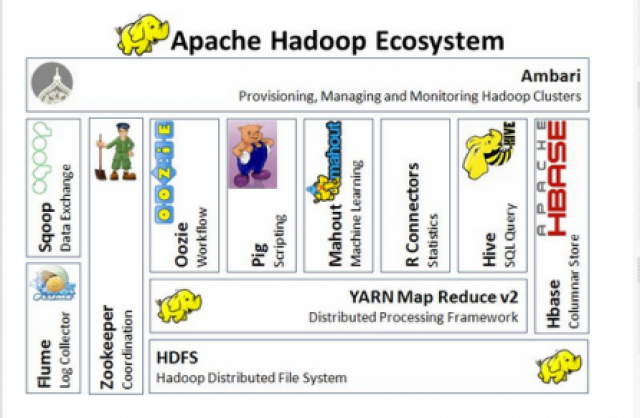
In addition to HDFS, YARN and MapReduce, the Hadoop ecosystem consists of a number of useful projects such as Apache Pig, Apache Hive, Apache HBase, and others. These projects help to perform various operations such as querying, searching, iterative analysis etc. Figure 1 shows the Hadoop ecosystem.
Figure.1 - Hadoop Ecosystem
IBM Bluemix
IBM Bluemix is an open standards, cloud based PaaS for building, running and managing applications. Several programming languages, services and development tools are supported by IBM Bluemix to build, run, deploy and manage applications in the cloud.
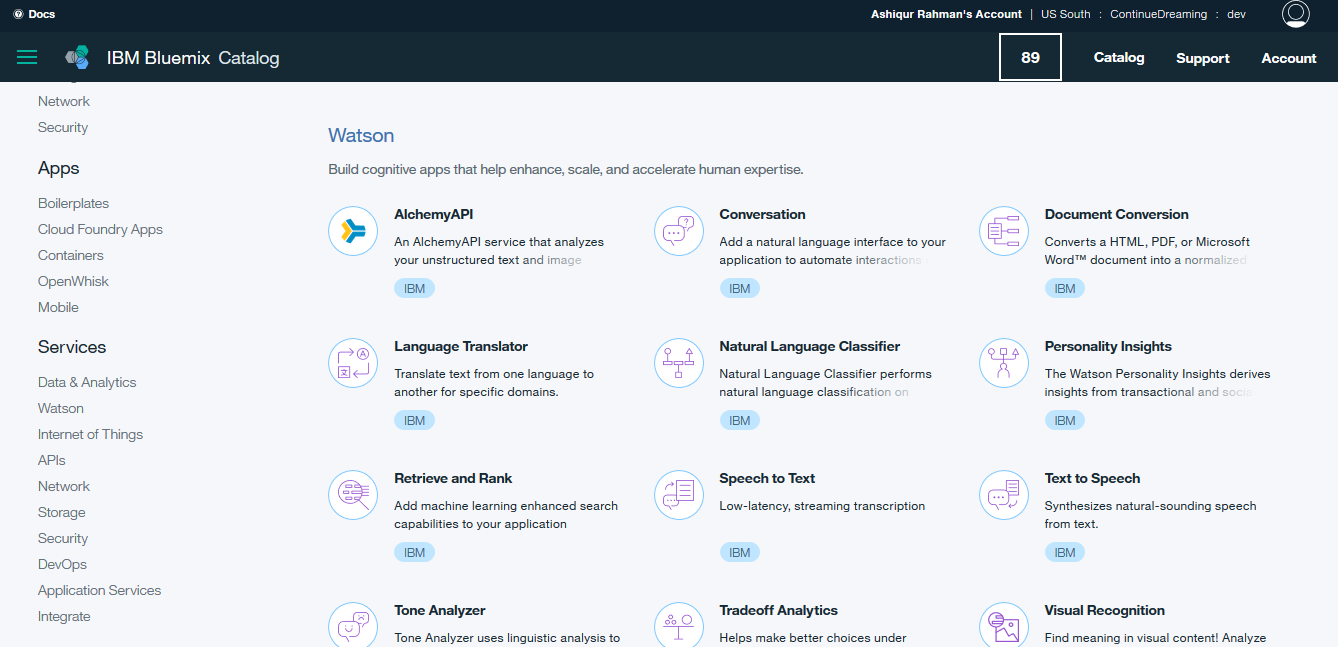
Java, Node.js, Go, PHP, Swift, Python, Ruby Sinatra, Ruby on Rails are currently supported programming languages by IBM Bluemix. It can also be extended to support other languages such as Scala. Besides, different categories of services such as Watson, InternetOfThings, Network, Security and others are supported by IBM Bluemix. Its apps include Cloud Foundry, mobile apps etc. A Bluemix account is needed to access the services offered by IBM Bluemix. Figure 2 presents the catalog interface of IBM Bluemix. As can be seen from the interface there are different services under different categories.
Figure.2 - IBM Bluemix Catalog Interface
BigInsights
BigInsights is a software platform for discovering, analyzing, and visualizing data from various sources. It provides a collection of value-added services that can be installed on top of the IBM Open Platform with Apache Hadoop. Application developers, data scientists, business analysts and other interested users can develop and run custom analytics to get insights from big data using BigInsights. This data is often integrated into existing databases, data warehouses, and business intelligence infrastructure. Through its tools and value-added services BigInsights simplify development and maintenance. Software developers can use the value-added services to analyze loosely structured and unstructured data. Besides, data analysis tools can be used by data scientists and business analysts to explore and work with unstructured data in a familiar environment. It saves organizations from creating their own Hadoop infrastructure. They can simply buy and use the services from IBM Bluemix.
Creating BigInsights for Apache Hadoop service in IBM Bluemix
IBM Bluemix provides support for creating BigInsights for Apache Hadoop service. To use that service a user needs to have an IBM Bluemix account. Then he can use the Bluemix web interface for creating the service.
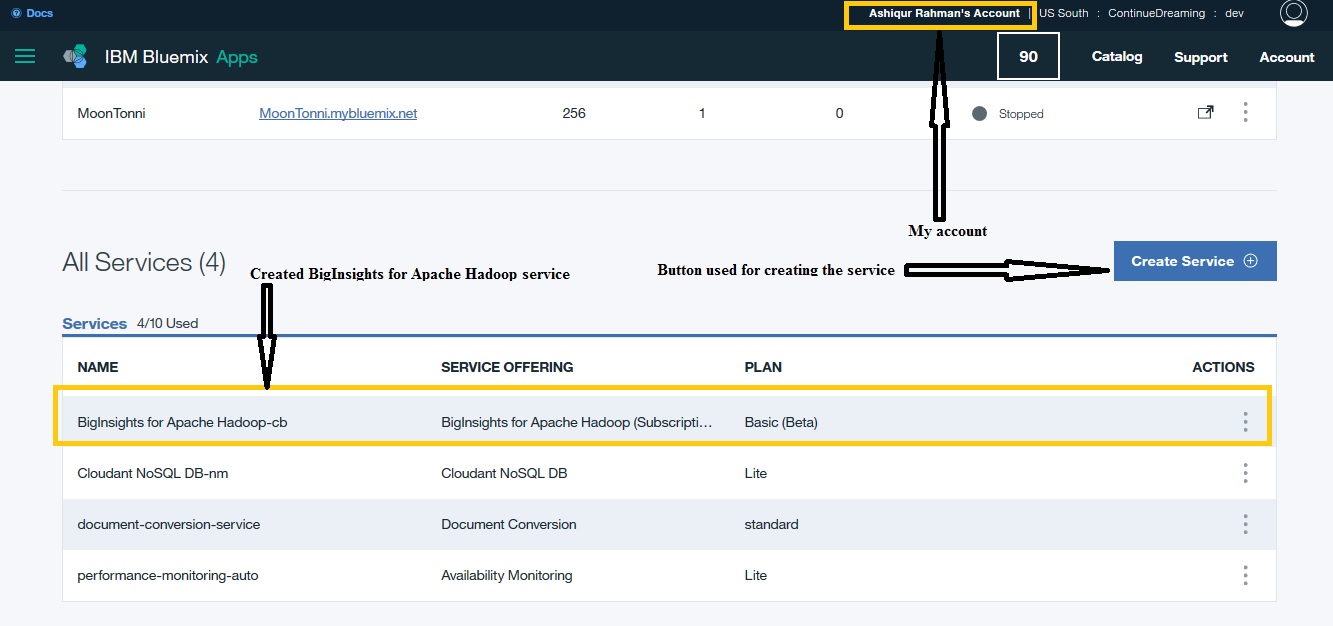
As can be seen in Figure 3, inside my IBM Bluemix account a BigInsights service named BigInsights for Apache Hadoop-db was created for using the Hadoop service. The Create Service button provides the list of services that a user can access.
Figure.3 - Apache Hadoop Service in IBM Bluemix
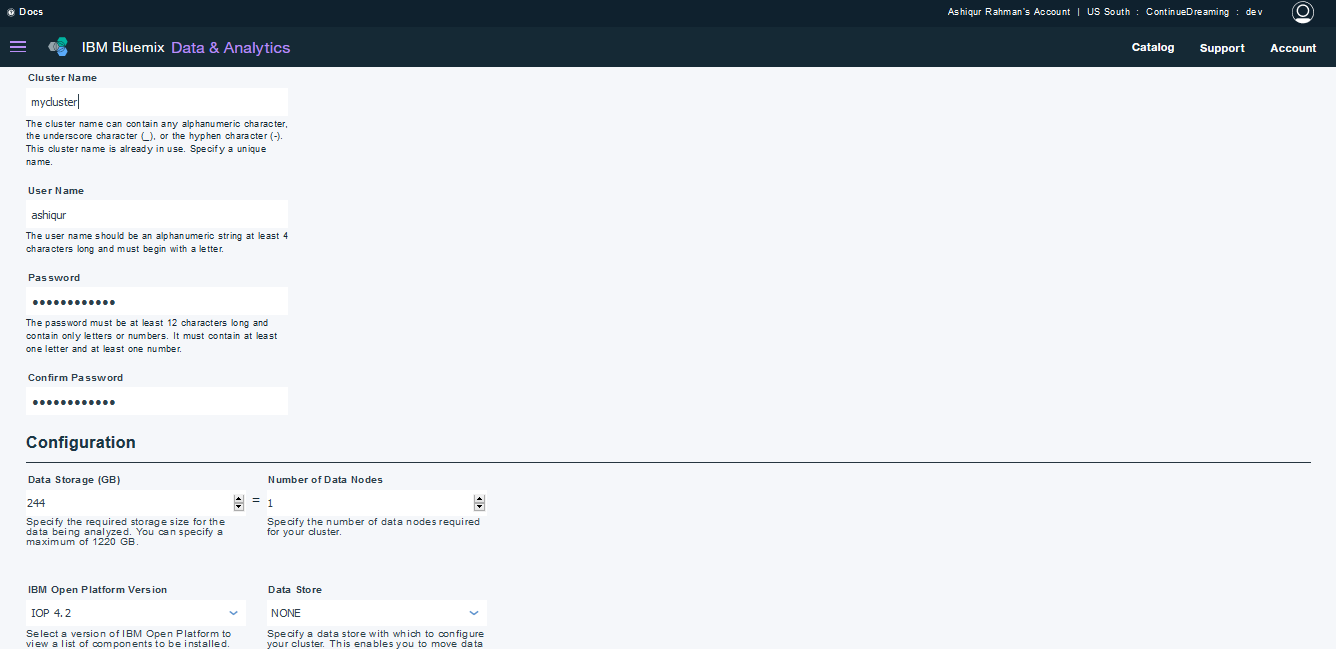
After creating the service, a cluster named mycluster was created for working. During this step one needs to provide configuration and some other information. Figure 4 shows that step.
Figure.4 - Cluster Creation
Sentiment Analysis Using MapReduce Programming Framework
In this project, a list of positive words, negative words and customers’ reviews of products are used as source data. It finds the overall sentiment, either positive or negative, of each product. Each review had the following fields.
<member id> \t <product id> \t <date> \t <number of helpful feedbacks> \t <number of feedbacks> \t <rating> \t <title> \t <body>
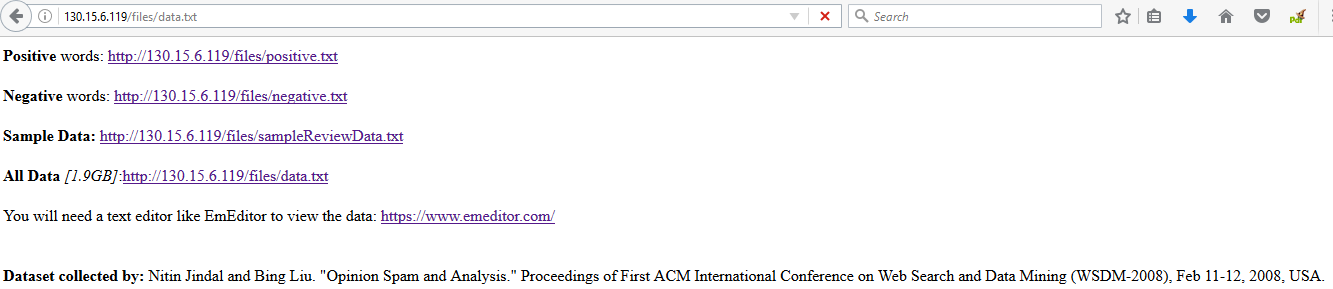
The data files were collected from http://130.15.6.119/ [Hu, M., & Liu, B. (2004, August). Mining and summarizing customer reviews]. Figure 5 shows the web interface from where the data files were collected.
Figure.5 - Source of Data
The file containing sample data was renamed to “sample.txt” and the file containing all data was renamed to “alldata.txt” for easy identification during this analysis process. In fact, sample.txt is a subset of alldata.txt.
To implement the sentiment analysis process in MapReduce framework, at first, an algorithm was developed to find the sentiment from a piece of text. Then a MapReduce program was written using Java in Eclipse IDE. Finally, it was employed on the MapReduce framework in Hadoop environment to find the overall sentiment of each product.
This section describes the developed sentiment analysis algorithm, MapReduce program for sentiment analysis, their execution in Hadoop and testing in detail.
Algorithm for determining the sentiment of a piece of text:
To find the sentiment of a piece of text the Algorithm1: SA, was developed. It takes a piece of text, a list of positive words and a list of negative words as input. It analyzes the given piece of text, and for each positive word it adds 1 to positiveSentiment and for each negative word it adds 1 to negativeSentiment. When this process finishes it subtract the negativeSentiment score from the positiveSentiment score and determines the overallSentiment of the text. The final output from this algorithm is a numerical value of the overallSentiment of the given text.
Algorithm1: SA (Finds the Sentiment of a Piece of Text) Input: A piece of text, positive word list, negative word list
- positiveSentiment = 0
- negativeSentiment = 0
- overallSentiment = 0
- for each word in the text{
- search the word in positive word list
- if the word is found in the positive word list then
- add 1 to PositiveSentiment
- else{
- search the word in the negate word list
- if the word is found in the negative word list then
- add 1 to NegativeSentiment
- }
- }
- overallSentiment = positiveSentiment – negativeSentiment Output: Numerical value representing the sentiment of the given text
MapReduce Program Development
Hadoop provides various library features as Java *.jar files such as hadoop-mapreduce-client-app-2.7.3.jar, hadoop-common-2.7.3.jar etc. These library files provide necessary classes, methods and interfaces for implementing MapReduce program in Java. Three separate source files named SentimentDriver.java, SentimentMapper.java and SentimentReducer.java were created to implement the MapReduce program using necessary classes and interfaces. Eclipse IDE was used for the development. As can be seen in Figure 6, various *.jar files provided by Hadoop for developing my MapReduce program were added and imported to use in source code as needed.
Figure.6 - Development Environment Using Hadoop Provided Packages
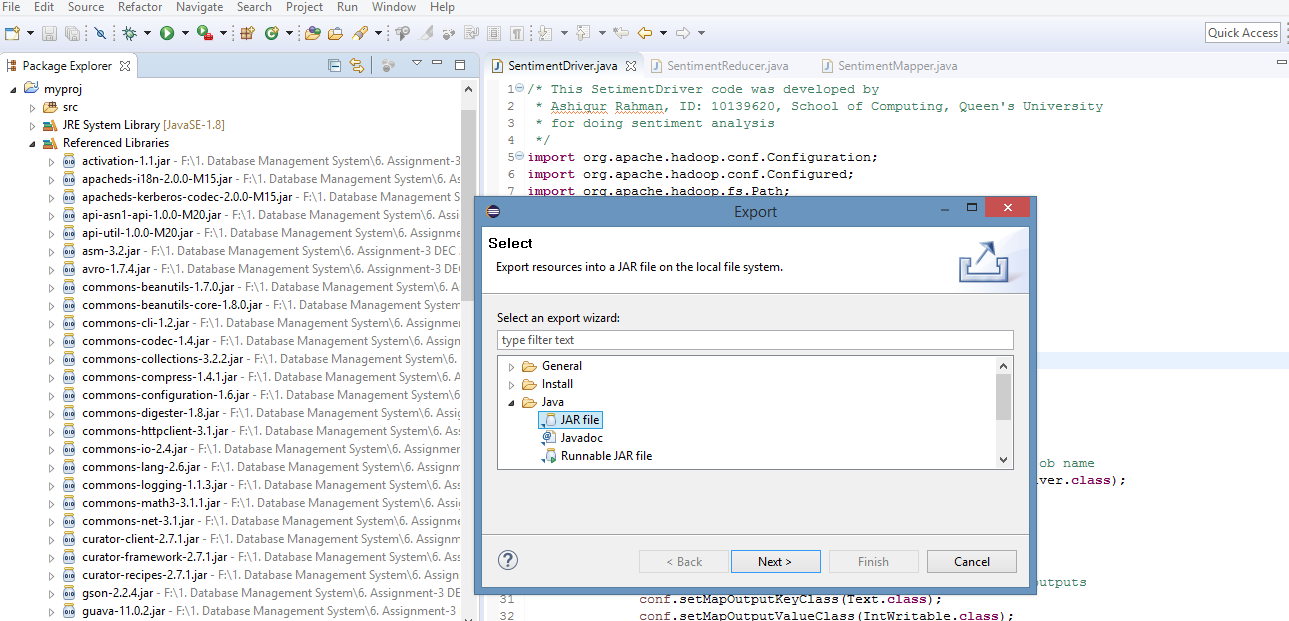
After finishing code development, SentimentAnalysis.jar file was created following the Export facilities of the Eclipse IDE. Figure 7 shows the interface that helps to create the *.jar file. To run MapReduce job in Hadoop *.jar of the source is required.
Figure.7 - Creating the *.jar file
Next the Map phase and the Reduce phase of the developed SentimentAnalysis program is described in detail.
The Map Phase
The function of the Map phase is to process the input in order to produce output in the form of <key, value> pairs for the Reducer. During the mapping process
Algorithm2: Map Phase Input: Each record from the source file in HDFS
- read a record
- find product_id and body of the review
- find overallSentiment value by applying SA algorithm on review body
- emit(product_id, overallSentiment) Output: Product id and overall sentiment value as (key, value) pairs
The Reduce Phase
The Reducer gets sorted <key, value> pairs as input and produces <key’, value’> pairs as output. In the Reducer program for each particular key all of its sentiment values (positive and negative scores) were added together to get the final sentiment of the related product. If the final sentiment is greater than or equal to zero then the reducer produces <product_id, “Positive”> otherwise <product_id, “Negative”> as <key’, value’> pair. It can be mentioned that the assignment asks to find either positive or negative sentiment so the value Zero was considered in the positive group. Table 3 gives the Reduce Phase algorithm used for the reducer.
Algorithm3: Reduce Phase Input: Sorted (Key, Value) pairs
- receive each product_id and all of its associated overallSentiment value
- find finalSentiment of the product id by adding all of its overallSentiment
- if finalSentiment >=0 then
- emit (product_id, “Positive”)
- else
- emit (product_id, “Negative”) Output: Product id and its sentiment as (Key, Value) pairs
Uploading files to the Server
After finishing the program development process, all files including the developed jar and data files were needed to upload to the server. PuTTY PSCP was used to upload the files to the server from local storage. PSCP has the following format: “pscp [options] source destination”. Below a sample of using PSCP for uploading a file to the server is shown. This technique was followed to upload all the files: SentimentAnalysis.jar, positive.txt, negative.txt, sample.txt and alldata.txt.
C:\Users\ASR\Desktop\putty>pscp f:/myjar/hadoop-mapreduce-examples-2.7.3.jar ashiqur@bi-hadoop-prod-4257.bi.services.us-south.bluemix.net:/tmp
ashiqur@bi-hadoop-prod-4257.bi.services.us-south.bluemix.net's password:
hadoop-mapreduce-examples | 288 kB | 288.9 kB/s | ETA: 00:00:00 | 100%
To run a MapReduce job all required input files must be in the HDFS directory. Below a sample of uploading the data files to the HDFS directory using “haddop fs
login as: ashiqur
ashiqur@bi-hadoop-prod-4257.bi.services.us-south.bluemix.net's password:
IBM's internal systems must only be used for conducting IBM's business or for purposes authorized by IBM management
Use is subject to audit at any time by IBM management
-bash-4.1$ cd \
>
-bash-4.1$ pwd
/home/ashiqur
-bash-4.1$ cd /
-bash-4.1$ cd /tmp
-bash-4.1$ hadoop fs -put /tmp/alldata.txt /tmp/data
-bash-4.1$ hadoop fs -put /tmp/positive.txt /tmp/data
-bash-4.1$ hadoop fs -put /tmp/negative.txt /tmp/data
Running a sample MapReduce Job:
To run a MapReduce job in Hadoop “$yarn jar
-bash-4.1$ yarn jar WordCount.jar /tmp/testfolder /tmp/testresult
16/11/05 05:12:43 INFO impl.TimelineClientImpl: Timeline service address: http://bi-hadoop-prod-4257.bi.services.us-south.bluemix.net:8188/ws/v1/timeline/
16/11/05 05:12:44 INFO client.RMProxy: Connecting to ResourceManager at bi-hadoop-prod-4257.bi.services.us-south.bluemix.net/172.16.106.1:8050
16/11/05 05:12:44 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/11/05 05:12:45 INFO input.FileInputFormat: Total input paths to process : 1
16/11/05 05:12:45 INFO mapreduce.JobSubmitter: number of splits:1
16/11/05 05:12:45 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1478151346791_0024
16/11/05 05:12:45 INFO impl.YarnClientImpl: Submitted application application_1478151346791_0024
16/11/05 05:12:45 INFO mapreduce.Job: The url to track the job: http://bi-hadoop-prod-4257.bi.services.us-south.bluemix.net:8088/proxy/application_1478151346791_0024/
16/11/05 05:12:45 INFO mapreduce.Job: Running job: job_1478151346791_0024
16/11/05 05:12:53 INFO mapreduce.Job: Job job_1478151346791_0024 running in uber mode : false
16/11/05 05:12:53 INFO mapreduce.Job: map 0% reduce 0%
16/11/05 05:13:01 INFO mapreduce.Job: map 100% reduce 0%
16/11/05 05:13:06 INFO mapreduce.Job: map 100% reduce 100%
16/11/05 05:13:07 INFO mapreduce.Job: Job job_1478151346791_0024 completed successfully
16/11/05 05:13:07 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=81
FILE: Number of bytes written=258975
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=211
HDFS: Number of bytes written=43
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=23040
Total time spent by all reduces in occupied slots (ms)=28936
Total time spent by all map tasks (ms)=5760
Total time spent by all reduce tasks (ms)=3617
Total vcore-milliseconds taken by all map tasks=5760
Total vcore-milliseconds taken by all reduce tasks=3617
Total megabyte-milliseconds taken by all map tasks=23592960
Total megabyte-milliseconds taken by all reduce tasks=29630464
Map-Reduce Framework
Map input records=8
Map output records=16
Map output bytes=122
Map output materialized bytes=81
Input split bytes=153
Combine input records=16
Combine output records=8
Reduce input groups=8
Reduce shuffle bytes=81
Reduce input records=8
Reduce output records=8
Spilled Records=16
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=623
CPU time spent (ms)=3300
Physical memory (bytes) snapshot=2308534272
Virtual memory (bytes) snapshot=14776082432
Total committed heap usage (bytes)=2801795072
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=58
File Output Format Counters
Bytes Written=43
-bash-4.1$ hdfs://bi-hadoop-prod-4257.bi.services.us-south.bluemix.net:8020/user/ashiqur/
Input and Output of the developed MapReduce program
The SentimentAnalysis.jar file accepts
-bash-4.1$ yarn jar SentimentAnalysis.jar /tmp/testfolder/positive.txt /tmp/testfolder/negative.txt /tmp/testfolder/alldata.txt /tmp/testresult
The output file get stored in the HDFS directory which is accessible and downloadable through the Ambari web interface. Below a few results obtained by analyzing alldata.txt is presented. The output file part-00000 provided in the output directory was generated by providing the positive.txt, negative.txt and alldata.txt files to the sentiment analysis program. It took only around 30 minutes to process the alldata.txt file of size 1.9 GB using the Hadoop MapReduce.
………………………………
B00000IN5R Positive
B00000IN5X Negative
B00000IN9Q Positive
B00000INAY Positive
B00000INAZ Positive
B00000INB0 Positive
B00000INB1 Positive
B00000INB2 Positive
B00000INB3 Positive
B00000INB4 Positive
B00000INB5 Positive
B00000INBA Positive
B00000INBC Positive
B00000INBI Positive
B00000INBZ Positive
B00000INCI Negative
B00000INCJ Positive
B00000INCK Negative
B00000INCM Positive
B00000INCN Negative
B00000INCO Positive
B00000INCP Negative
B00000INCR Positive
B00000INCS Negative
B00000INCW Negative
B00000IND0 Positive
…………Truncated…………